About Center
What is Materials Informatics?
The parameter space in materials research is vast. For instance, in the chemical space of organic small molecules, there are approximately 1060 possible candidate molecules. When extending research to the frontier, additional factors like additive selection, microstructure control, and sample preparation process variables further expand the design space exponentially. The goal of materials informatics (MI) is to identify the parameters that yield desired material properties within this expansive search space.
The basic workflow of MI involves two key challenges: the forward problem and the inverse problem. The forward problem entails predicting material properties based on composition, structure, and process variables. The inverse problem, on the other hand, seeks to predict the design variables that will yield desired properties by inverting the forward prediction model.
Researchers at the Materials Informatics Research Center have pioneered novel approaches to tackling forward and inverse problems in materials research by leveraging unique data science perspectives. Their work has advanced the development of data science methodologies and machine learning algorithms [1-7]. Moreover, they have contributed to the discovery of various new materials, including polymeric and quasiperiodic materials, through practical applications of these methods [8-14].
Lack of Data Resources for Data-Driven Materials Research
Compared to popular application fields of data science such as image recognition and natural language processing, data resources in materials research are extremely limited. Several factors contribute to this: (1) the high cost of data acquisition, (2) the challenge of constructing “common data” due to the vast and diverse parameter space, and (3) a lack of incentives to encourage data disclosure among researchers and institutions, which creates barriers to data sharing and collaboration. Given these challenges, the movement toward the co-creation of systematic open database has been slow. In the short to medium term, resolving the scarcity of data resources seems unlikely, as it requires significant cultural shifts within the research community. Furthermore, data often do not exist for truly innovative materials, meaning that interpolative prediction of conventional data science is insufficient for their discovery. Thus, many of the challenges in MI stem from the lack of data resources.
Our Missions
Data is the most critical resource in data-driven research. Every breakthrough in data-driven research and technology, such as generative AI and large-scale language models, has been fueled by vast amounts of data. AlphaFold, which revolutionized protein structure prediction, is a prime example—its success was built on over half a century of foundational data development in life sciences.
Figure 1 illustrates the center’s vision. Many researchers, particularly those in closed domains like university labs, face difficulties in acquiring the necessary data for data-driven research on their own. To address this challenge, we must develop a comprehensive open database for various material systems. This can be achieved through computational experiments based on first principles or molecular dynamics, and high-throughput robotic experiments. Researchers can then overcome data limitations by integrating and analyzing their laboratory’s data alongside foundational data from open domains.
Our mission is twofold: to develop foundational open-domain data and to create data science methodologies and machine learning algorithms for the integrated analysis of heterogeneous data in open and closed domains. Data is like an infinitely increasable oil—its quantity and diversity continuously increase, creating ever-expanding possibilities for data science. However, this also creates a gap between those with access to data and those without. Data-driven research, at its core, becomes a power game.
In the complex landscape where big data and small data intersect, we aim to define what MI should represent. In a transdisciplinary area like data-driven research, competitive research by small groups is inherently limited. To overcome these limitations, it is essential for researchers across disciplines, organizations, and borders to share resources, knowledge, and technologies. Through this collective knowledge and co-creation, we can unlock new possibilities. The Research Center for Materials Informatics, in collaboration with researchers from both industry and academia, will serve as a hub for the development of new fields in materials science, fostering innovation through co-creation and the fusion of diverse expertise.
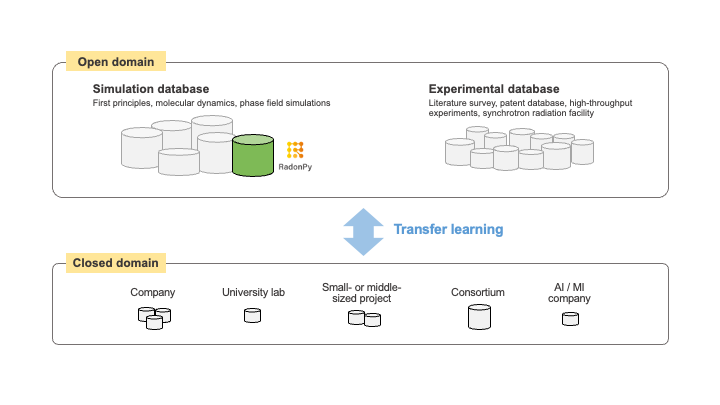 Figure 1: Our mission is to develop foundational infrastructure data for data-driven materials research and to create machine learning methodologies and algorithms that integrate data from both open and closed domains.
Figure 1: Our mission is to develop foundational infrastructure data for data-driven materials research and to create machine learning methodologies and algorithms that integrate data from both open and closed domains.
References
[1] Ikebata et al., J Comput Aided Mol Des 31, 379–391 (2017).
[2] Yamada et al., ACS Cent Sci 5, 1717–1730 (2019).
[3] Aoki et al., Macromolecules 56, 5446–5456 (2023).
[4] Minami et al., Adv Neural Inf Process Syst 30 (2023).
[5] Hayashi et al., npj Comput Mater 8, 222 (2022).
[6] Kusaba et al., Comput Mater Sci 211, 111496 (2022).
[7] Noda et al., arXiv, arXiv:2404.08657 (2024).
[8] Wu et al., npj Comput Mater 5, 66 (2019).
[9] Liu et al., Adv Mater 33, 2102507 (2021).
[10] Liu et al., Phys Rev Mater 7, 093805 (2023).
[11] Uryu et al., Adv Sci 11, 2304546 (2024).
[12] Ju et al.. Phys Rev Mater 5, 053801 (2021).
[13] Maeda et al., ChemRxiv 10.26434/chemrxiv-2024-tj786 (2024).
[14] Nanjo et al.. arXiv, arXiv:2408.05135 (2024).
Establishment Time
1st March, 2024